Product
LLMWhisperer, the best OCR text recognition software for AI-based Document extraction workflows
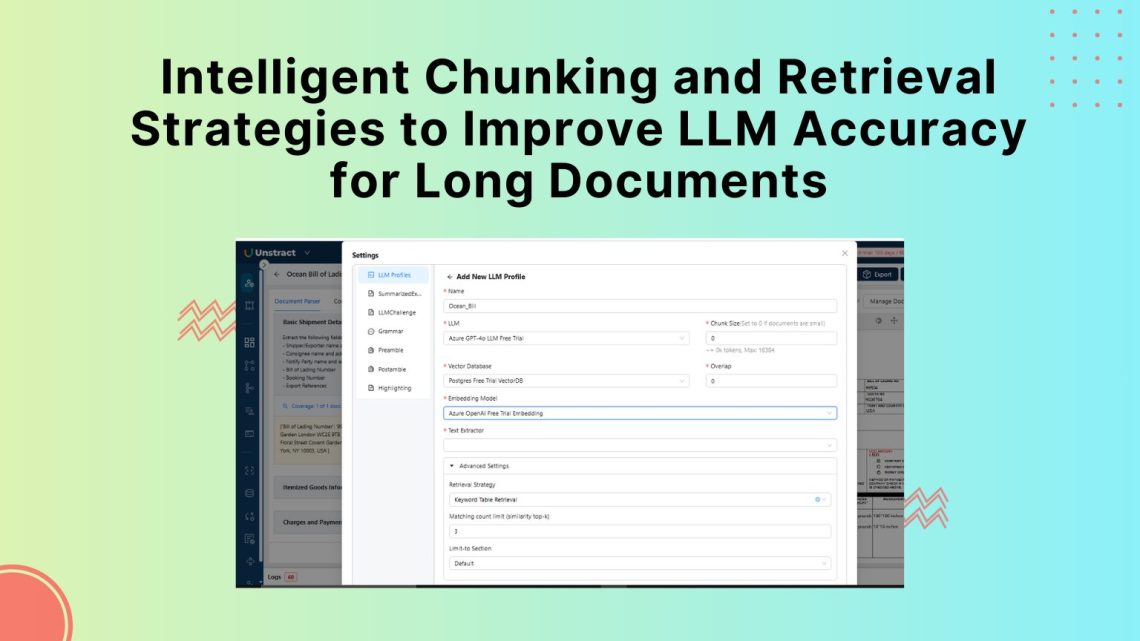
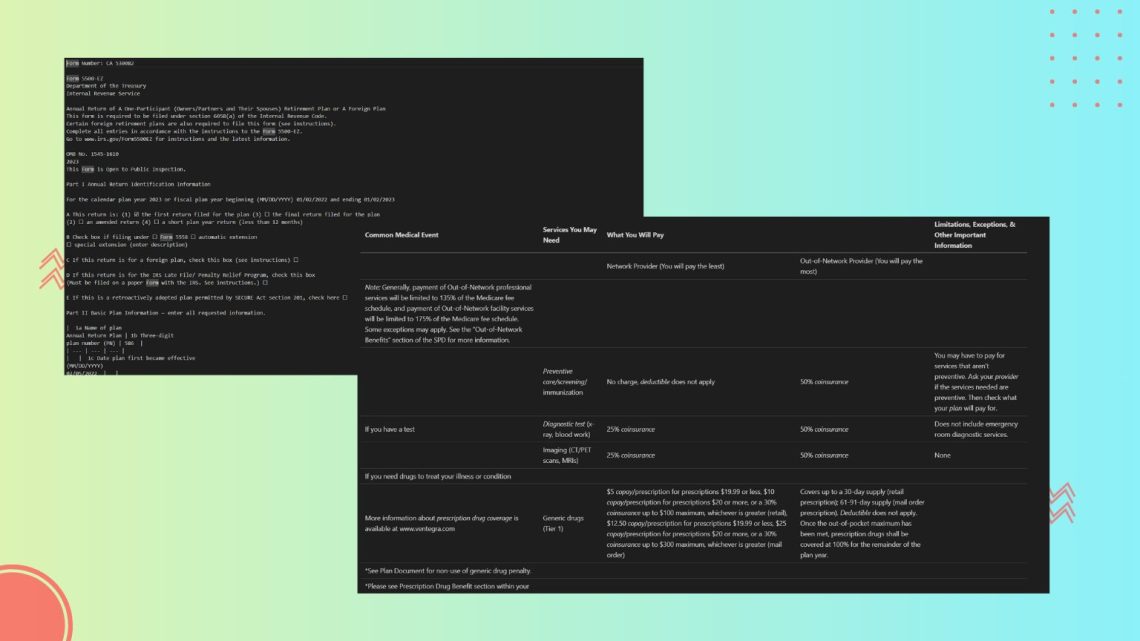
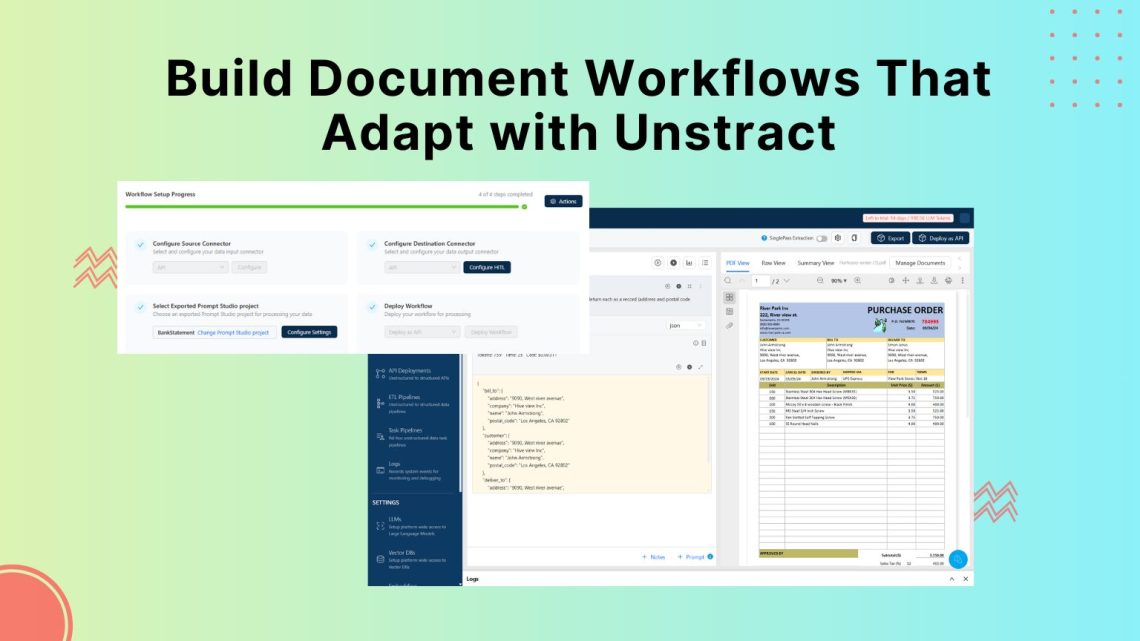
LLMs and vision-language models depend on clean, structured inputs for accurate results. Discover how OCR text recognition with LLMWhisperer preserves layout and improves document understanding for reliable data extraction.