Product
Guide to Extracting Data from PDF Form with Unstract
This piece explores the difficulties of processing PDFs with form fields and showcases how large language models (LLMs) offer innovative approaches to fillable field data extraction.

This piece explores the difficulties of processing PDFs with form fields and showcases how large language models (LLMs) offer innovative approaches to fillable field data extraction.
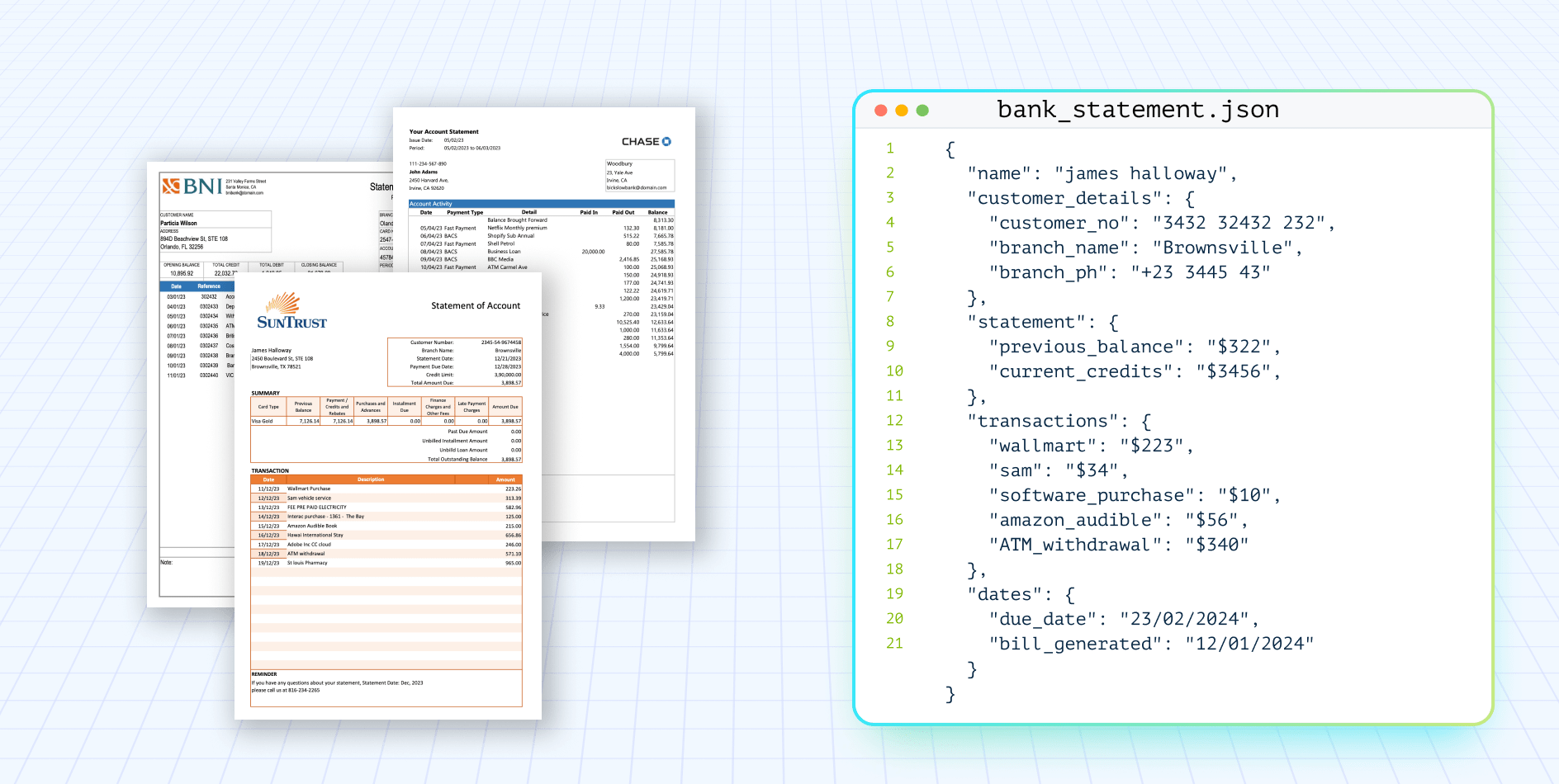
This piece explores the difficulties in bank statement processing and showcases how Large Language Models (LLMs) offer innovative approaches to bank statement data extraction

A Comprehensive Guide to Optical Character Recognition (OCR) Using Tesseract. In this detailed guide, we will configure Tesseract and delve into its features and capabilities by examining three different document scenarios

A modern guide to extracting data from PDF documents and transforming it into JSON using Unstract. Converting PDFs to JSON not only improves data accessibility and usability but also unlocks new opportunities for automation, analytics, and seamless integration into broader business workflows.

Engineers becoming product managers is a potentially dangerous idea. The reason behind this is simple—knowing too much about the tech,
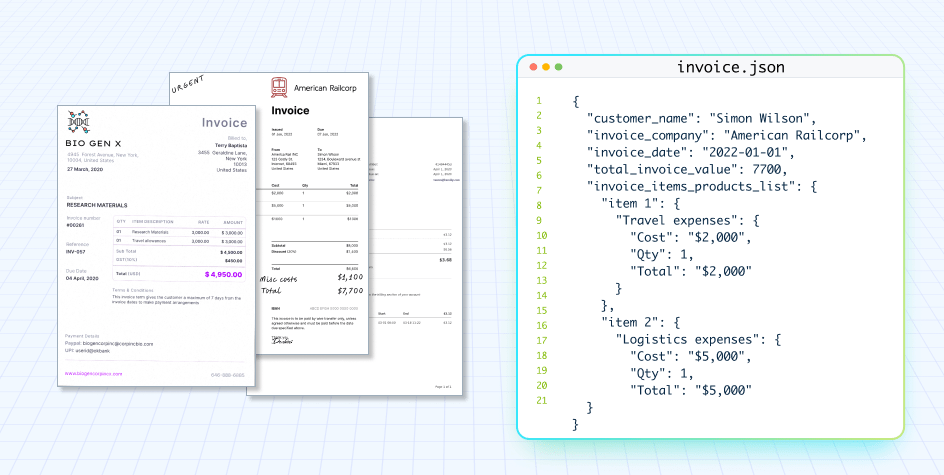
This piece explores the difficulties in invoice processing and showcases how Large Language Models (LLMs) offer innovative approaches to invoice data extraction